Actualizado 16 ene 2026. Razón : Nuevas instancias creadas en ovhcloud obligan a dar rodeos en pm2.
Actualizado 21 mar 2026. Razón : Hice una version DIsponible en github que es mas facil de leer. Junté por lo mismo dos POSTS aquí.
https://github.com/AlfonsoOrozcoAguilarnoNDA/snippetsMIT/blob/main/instalar_LAMP_react_node_quarkus_gitea_debian13.md
La información de aquí es mas descriptiva, pero la opción del repositorio tiene todo el contenido DE ESTE POST, sin comentarios y expresado diferente.
PARTE UNO
ACTUALIZACIÓN CRÍTICA – 16 enero 2026
Nuevas instancias de OVHcloud (enero 2026) tienen problemas graves de inconsistencia. Un servidor levantado la semana pasada funciona con PM2, uno levantado hoy NO. Este manual funciona al 100% en Vultr. En OVHcloud solo es confiable para LAMP básico o para respaldo de archivos por el espacio de disco duro barato.
El Problema Real con OVHcloud
Las políticas de OVHcloud te obligan a usar un usuario intermedio llamado ‘debian’, no root directo. Esto significa:
- Tienes que usar nvm con permisos limitados
- Los módulos pueden bloquearse por el shell intermedio
- Pagas por un servidor pero no eres realmente root
Pero el problema crítico es otro: OVH maneja cambios en sus capas de abstracción de seguridad sin avisar y sin consistencia. Vultr te da una instancia desnuda. OVHcloud te da una caja negra que cambia cada semana.
Problemas verificados de OVHcloud:
1. Capas de seguridad inconsistentes entre servidores
2. Reputación de spammers (tus correos caerán en spam)
3. Panel de control confuso
4. Soporte técnico deficiente
5. Bloqueos arbitrarios de herramientas (PM2, permisos de NPM)
La pregunta que debes hacerte:
Si tu plataforma no es reproducible entre servidores del MISMO proveedor, ¿qué estás haciendo ahí?
OVHcloud te fuerza a usar systemd en lugar de PM2. Aunque técnicamente funciona, pierdes las ventajas críticas de PM2:
- Monitoreo en tiempo real con pm2 monit
- Reinicio automático inteligente
- Logs centralizados y fáciles de consultar
- Gestión de múltiples procesos Node con un comando
No usar PM2 es darte un tiro en el pie. Como dice el refrán en México: «es ir a la guerra sin fusil».
Tus opciones:
1. Cambiar de proveedor (recomendado) – Te tomará 6+ horas por el vendor lock-in que crean las abstracciones
2. Contratar a alguien que conozca las limitaciones específicas de OVH (caro e innecesario)
3. Usar OVHcloud SOLO para LAMP básico (WordPress, Laravel sin Node)
4. Regresar tu servidor actual a LAMP limpio (ver Anexo 3)
Este problema no eres tú. No es falta de conocimiento. Es la plataforma. Lo mismo pasa con Azure y es peor con RHEL.
Recomendación profesional:
- Usa OVHcloud para: WordPress, Laravel, aplicaciones PHP puras. Respaldos no criticos.
- NO uses OVHcloud para: Node.js, React con SSR, PM2, Spring Boot con gestión de procesos compleja
Si tienes dudas, sigue los pasos del Anexo 3 para borrar React, NPM, Vite y PM2, y úsalo como servidor LAMP tradicional. Es mejor un servidor simple que funciona que una «plataforma moderna» que falla aleatoriamente.
Las órdenes para regresar a servidor LAMP limpio y quitar todo lo relacionado con Node están en el Anexo 3.
En esta ocasión voy a levantar tres servidores LAMP con react y GITEA configurado, como base para springboot.
Siendo sinceros voy acorrer el proceso en dos servidores recién levantados y revisar que pasa con un tercero; los tres son de mi cliente, y van a ser uno ya existente en ovhcloud, uno nuevo en ovhcloud, y un tercero en vultr, con 8gb ,6gb y 4 gb respectivamente.
Quiero dejar claro que las politicas de ovhcloud son usar un usuario intermedio llamado debian, con lo cual debes correr ordenes nvm. Si funciona pero hay que moverle. En realidad estas pagando por algo que no es root. Si mas espacio. Pero si los modulos no se carga porque un shell los bloquea no es culpa de este manual. Si las imagenes nuevas te dan capas de seguridad inconsistente hay un problema serio. Tu plataforma no es reproducible.. entre el mismo proveedor.
En casos como Ovhcloud la abstracción te lleva a mejor usar como servicios de Systemd independientes en lugar de confiar en gestores de procesos de nivel de usuario como PM2. Systemd es agnóstico a las capas de shell de OVH y garantiza que el binario arranque con los privilegios correctos del sistema. Pero a veces tienes razones para no usar systemd. OVH te obliga. O te obligaa usar una versión de npm y nvm. O no te deja dar un apt update.
Las razones de tres instalaciones a la vez?
- a ) No van a usar el de 4gb en producción Probablemente uno de sus docker kubernetes es para pruebas. Lo pueden subir en memoria si quieren después
- b ) Spring/springboot ocupa relativamente mucha memoria, pero para lo que realmente lo usan la carga del peso debería ser mantener springboot funcionando y no tienen tantos clientes.
- c ) Mi lógica es que probablemente tampoco tienen optimizada la base de datos, y estoy casi seguro que el problema del servidor de 8 es que no le corren actualizaciones desde hace mucho. (Editado… si, el de 8gb todavía tiene debian 11)
- d ) Para su volumen de clientes no necesitan NGINX, y como tienen wordpress apache es mejor. Por cierto que ya puse por aqui un manual de LEMP o sea lo mismo pero con NGINX pero sin springboot y usando quarkus en su lugar.
- e ) OVHCloud no lo recomiendo por permitir spammers. Pero el cliente está a gusto con el, y ya tiene algunos servidores de apoyo y de python allí.
Base deseada:
- Parte 1
- Servidor en debian 13 por ser una de las distros grandes y ya estan familiarizados con gestor de paquetes apt, además que es mi recomendación habitual.
- Php 8.4 con librerias importantes
- mariadb con seis bases de datos y usuario particular
- Certbot SSL con auttorenovación de dry run
- Node y react
- Gitea sin cerrar
- Parte 2
- Gitea Cerrado
- Certbot SSL con autorenovación de dry run en subdominio .git
- hacer un archivo simple en php que me muestre uso de servidor en ram y disco duro
- Instalar spring boot
- Verificar que springboot este funcionando
- DESPUES verificar en el simple de php que me muestre uso de servidor en ram y disco duro
- Probablemente un «hola mundo» en hibernate
- Parte 3 si me da tiempo
- Cargar Quarkus Dev
- Configurar un sistema en Gradle / Hibernate / Thymeleaf como prueba de concepto en una parte 4 sin maven y sin react
Preparativos.
- Para cada servidor:
- Por sencillez Usaremos la clave de root que da el panel de control y la escribiremos
- Configurar git.tu-dominio.com
- Preparar una contraseña para root mariadb
- Preparar una contraseña para usuario admin de sql, siempre sugiero usar usuario adminsql
- Preparar una contraseña para usuario gitea2 que va a ser el admin
Empezaré usando como plantilla lo que hago en vultr, asi que usare vultre 80gb disco, 4 gb ram para el ejemplo.
Muy Importante:
cuando los proveedores intentan «simplificar» la seguridad creando capas de permisos extrañas, terminan rompiendo el flujo estándar de herramientas como React o Node.
Lo que mencionas del «usuario con mucho sudo sin ser root» es la receta perfecta para el desastre en despliegues. Muchas imágenes modernas intentan forzar políticas de seguridad que chocan con la forma en que los manejadores de paquetes (como npm) gestionan permisos en carpetas globales. Si el entorno no es limpio y el usuario no tiene la jerarquía clara, terminas peleando con el sistema operativo en lugar de programar.
Si no tienes root y tu terminal no tiene permisos no eres root. Punto. (eso pasa en 1and1 casi siempre y en ovhcloud 50% de las veces).
Nota: es posible que algun guion haya cambiado de forma, en curl. son guiones normales. Lo mismo con las comillas.
Costo? Como anoté en las tres primeras partes esto fue un encargo para cliente. Desde el momento enb que entré a terminal en máquina limpia, hasta que cloné en la parte 5 fueron poco menos de tres días y no dedicados a esto..
La eficiencia técnica se traduce directamente en agilidad económica: mientras que el costo operativo de este stack en Vultr es de apenas 20 USD al mes, el proceso completo de implementación, desde el inicio de la configuración hasta la generación y clonación de la imagen final para el cliente, representó un gasto ínfimo de tan solo 2.33 USD. Esta cifra no solo cubre el tiempo de cómputo, sino también la transferencia de datos entre servidores durante el despliegue de la imagen maestra.
Es la prueba de que un servidor de alta densidad, basado en Debian 13 y optimizado quirúrgicamente, permite realizar despliegues masivos y entregas de infraestructura crítica por una fracción del costo de los proveedores tradicionales. No es solo gastar menos, es la capacidad de replicar entornos profesionales de producción en cuestión de minutos y por el precio de un café, manteniendo la soberanía total sobre el sistema y los datos del cliente.
 Alcance de Este Manual
Alcance de Este Manual
Este es un manual simple y reproducible para levantar un stack funcional. No es una guía exhaustiva de configuración avanzada.
Lo que NO cubre este manual (intencionalmente):
1. Configuración de .env en React
- Las variables de entorno son específicas de cada proyecto
- Configurarlas mal puede exponer credenciales sensibles
- Si ya tienes un servidor existente en producción, experimentar con
.env puede romper cosas
- Aprende esto en un ambiente de desarrollo local primero, no en producción
2. Servidor de correo (SMTP)
- OVH Cloud: Tiene fama de spammers, tus correos caerán en spam o serán bloqueados
- Vultr: El puerto 25 (SMTP) está cerrado por defecto, necesitas contactar soporte para que te lo abran
- Configurar SMTP mal puede convertir tu servidor en zombi de spam (y quedar en blacklists globales)
- Si necesitas correo, usa servicios externos como SendGrid, Mailgun o AWS SES. Yo recomiendo Twilio.
3. Configuraciones avanzadas de seguridad
- Hardening exhaustivo de cada servicio
- Configuración de WAF (Web Application Firewall)
- Intrusion Detection Systems (IDS)
- Estas son importantes, pero cada una requiere su propio manual
4 Lo que SÍ cubre:
- Stack completo: Apache + Node + React + Gitea + MariaDB
- Seguridad básica pero sólida (UFW, permisos correctos)
- Configuraciones que funcionan «out of the box»
- PM2 para inmortalidad de procesos
- Control de versiones con Gitea (soberanía sobre tu código)
Si necesitas más, este manual te dio la base para investigar sin romper cosas.
Notas:
- Algunas partes de este manual por wordpress se cambian comillas debiendo ser ‘ comilla simple, noes error mio sin ode wordpress.
- Algunos hosts como ovhcloude te obligan a usarun alias no root, asi que todas las ordenes que siguen debes poner un «sudo» antes. Por simplicidad no la pongo en cada caso, y ya comente que recomiendo no usar ovhcloud (barato pero confuso su panel de control y poco soporte)
Voy haciendo en paralelo con el debian que ya subí de 11 a 13 en ovhcloud (previo respaldo claro). El enfasis lo pondré en vultr porque es lo que recomiendo y me interesa mas ver para entorno de pruebas del cliente ver como se comporta con poca memoria spring .Como tengo tres monitores, dejare para despues el de ovhcloud desde cero usando esta guia y si tengo que actualizar algo lo hago, pero la idea es vultr nuevo y debian 11/13 y wordpress abierto en cada monitor.
Por el stress, voy a poner un cambio eso si en el mysql para reducir memoria. ( ajustar el innodb_buffer_pool_size a unos 512MB o 1GB máximo para dejarle aire a la JVM de Spring. )
- apt update && apt upgrade -y # Paso 1 instalar y actualizar
- apt install apache2 php8.4 php8.4-mysql mariadb-server -y # Paso 2 Instalamos stack LAMP
- apt install php8.4-curl php8.4-gd php8.4-mbstring php8.4-xml php8.4-zip -y # extensiones comunes php
- apt install php8.4-bcmath php8.4-gd php8.4-xml -y # extensiones comunes php parte 2
- # Habilitar módulos Apache
- a2enmod rewrite
- a2enmod ssl
- systemctl restart apache2
- # Reiniciar PHP-FPM
- systemctl restart php8.4-fpm # probablemente te marque error ovhcloud revisa php -v
- systemctl enable php8.4-fpm
- apt install ufw -y # actualizamos firewall basico y lo hacemos dos veces por si las dudas …
- ufw default deny incoming
- ufw default allow outgoing
- ufw allow ssh
- ufw allow http
- ufw allow https
- ufw allow 22/tcp # SSH por si las dudas
- ufw allow 80/tcp # HTTP por si las dudas
- ufw allow 443/tcp # HTTPS por si las dudas
- ufw enable
- apt install certbot python3-certbot-apache -y # instalamos certbot
- mysql_secure_installation # volvemos seguro maria db pero
Nota: Si el punto anterior nos da error, es porque es porque es modo puro debian y no es ubuntu. a manita. Anexo 1 que está hasta abajo.
Seguimos.
Tenemos que crear un directorio para la aplicación en este caso wordpress.
- mkdir -p /var/www/tu-dominio.com
- chown -R www-data:www-data /var/www/tu-dominio.com
- chmod -R 755 /var/www/tu-dominio.com
Tenemos que configurar el dominio en apache:
- nano /etc/apache2/sites-available/tu-dominio.com.conf
Usando tu propia direccion de correo…
<VirtualHost *:80>
ServerName tu-dominio.com
ServerAlias www.tu-dominio.com
ServerAdmin admin@tu-dominio.com
DocumentRoot /var/www/tu-dominio.com
<Directory /var/www/tu-dominio.com>
Options -Indexes +FollowSymLinks
AllowOverride All
Require all granted
</Directory>
# Bloque específico para la App de React
# Esto asegura que Apache busque primero los archivos físicos
<Directory /var/www/tu-dominio.com/public_html/app>
RewriteEngine On
RewriteBase /app/
RewriteRule ^index\.html$ – [L]
RewriteCond %{REQUEST_FILENAME} !-f
RewriteCond %{REQUEST_FILENAME} !-d
RewriteRule . /app/index.html [L]
</Directory>
ErrorLog ${APACHE_LOG_DIR}/tu-dominio-error.log
CustomLog ${APACHE_LOG_DIR}/tu-dominio-access.log combined
</VirtualHost>
Una vez esto, recargar apache
Te recomiendo por tu propio bien que pongas algo en index.html de tu directorio public_html y algo en el de app que luego pondremos react. la razón es verificar AHORA y no en dos horas, que estas viendo lo que debe ser y no es un error de configuracion de virtual host. Algo tan simple como <h1>Hola!</h1> Sirve.
Y preparamos los procesos de certificado y revisar que se autorenueve. Te sugiero correr uno por uno y no en lote bash
- a2ensite tu-dominio.com.conf
- systemctl reload apache2
- apache2ctl configtest
- # la siguiente linea puede ser necesario que quites el paramatro apache
- certbot –apache -d tu-dominio.com -d www.tu-dominio.com
- # Verificar timer activo
- systemctl status certbot.timer
- # Ver próxima ejecución
- sudo systemctl list-timers | grep certbot # hay muchas maneras esta esoslo una
- # Probar renovación
- certbot renew –dry-run
El error mas común es que haya un error en el contenido de virtualhost como .com.com o algo similar, como las comillas.
Ahora entra a tu sitio y NO debes ver la pagina de Debian sino la tuya propia de public_html.
Lo que sigue es configurar las seis bases de datos de ejemplo, y mi ejemplo particular modificado, por lo que pongo una base de datos llamada carrito. Ese ss un ejemplo modificado sobre algo que anda cicrulando en internet y lo veremos en otro tema.
NOTA que estamos creando un usuario de maria/mysql nuevo para no usar root.
Entra a Mariadb con mariadb <enter>
— Crear las 6 bases originales + la del ejemplo «carrito»
CREATE DATABASE db_principal;
CREATE DATABASE db_gitea;
CREATE DATABASE db_spring_test;
CREATE DATABASE db_extra1;
CREATE DATABASE db_extra2;
CREATE DATABASE db_extra3;
CREATE DATABASE carrito;
— Crear el usuario particular que mencionamos en los preparativos
CREATE USER ‘adminsql’@’localhost’ IDENTIFIED BY ‘TuClaveSeguraAqui’;
— Darle permisos sobre todas las bases (o solo las necesarias)
— Para administración cómoda, le damos sobre todo el servidor local:
GRANT ALL PRIVILEGES ON *.* TO ‘adminsql’@’localhost’ WITH GRANT OPTION;
FLUSH PRIVILEGES;
SHOW DATABASES;
EXIT;
puedes verificar desde fuera que este creado como :
Para aplicar el cambio de los 512MB/1GB que mencionamos, recuerda editar:
nano /etc/mysql/mariadb.conf.d/50-server.cnf (o el archivo equivalente en tu instalación):
Ya que hicimos el cambio
- systemctl restart mariadb
- Entra a maria
- SHOW VARIABLES LIKE ‘innodb_buffer_pool_size’;
- exit;
Lamento decirte que a veces hay mas archivos de configuracion que los esperados. Asi que tu cambio probablemente te diga el valor…134217728 que significa que no cambio nada. Revisa el anexo 2 si tienes problemas. El número debería ser 536,870,912 (si pusiste 512M). Por el momento puedes seguir así pero no es error mio.
Instalar Node react y gitea
Paso 1: Instalación de Node.js 22 LTS y PM2
En Debian 13, queremos la versión más estable y moderna. No usaremos la de los repositorios estándar (que suele ser antigua), sino el repositorio oficial de NodeSource.
Configuraremos PM2 para que el servidor sea «autocurativo» (si una app de Node falla, PM2 la levanta en milisegundos).
React : Explicaremos cómo hacer el build de una app de React y cómo usar Apache para servir esos archivos estáticos de forma ultra rápida (sin pasar por Node, que es lo más eficiente).
Agregar el repositorio de Node.js 22
Ejecutamos esto para que el sistema sepa de dónde bajar la versión 22:
- curl -fsSL https://deb.nodesource.com/setup_22.x | sudo -E bash
- apt install -y nodejs
- #Verificamos dos veces:
- node -v
- npm -v
- v22.21.0 y 10.9.4 en mi caso
Prefiero el control directo sobre mis servidores; no me interesa ser esclavo de los Docker y Kubernetes ajenos. En lugar de añadir capas de abstracción que devoran tiempo en hardening y complican la operación, utilizo PM2 como mi gestor de procesos. Me da estabilidad, reinicios automáticos y monitoreo en tiempo real sin el lastre de una infraestructura pesada. Es reproducibilidad sin sobreingeniería: mantenemos el servidor vivo y eficiente, sin los costos ocultos ni las limitaciones de quienes dependen ciegamente de la nube.
Muchos programadores siguen tutoriales básicos o sobredimensionan con Docker cuando no lo necesitan, y otros instalan Node sin PM2. En lo personal, creo que PM2 es el punto medio ideal entre control, rapidez y flexibilidad.
Enlace de documentacion de pm2 https://pm2.keymetrics.io/docs/usage/quick-start/
Agregar PM2
- npm install pm2 -g # instalar pm2
Al ejecutar esta orden, vas a ver un «rombito» de progreso. Si no ves errores en letras rojas, déjalo correr. Todo va bien.
OJO: Normalmente, esto te da una línea larga que empieza con sudo env PATH… que tienes que copiar y pegar. Pero como Debian es otro nivel de eficiencia, a veces no te la pide porque detecta el sistema de inmediato. Si quieres forzarlo o asegurarte, usa:
En mi experiencia, como PM2 se integra tan bien con Debian, es probable que te diga que ya creó el root.service automáticamente (algo que he tenido que pelear más en Rocky Linux o Ubuntu).
ejecuta
Para revisar que ya está cargado, ejecuta:
- systemctl status pm2-root
Si el resultado es active (running), felicidades: ya tienes la infraestructura lista para que cualquier app de Node o React (vía SSR) se cargue solo si se cae o que sea inmortal.
Consejo experto:
Si quieres ver qué está pasando realmente ‘bajo el capó’ de tu servidor sin complicaciones, ejecuta el comando pm2 monit. Se abrirá un panel de control en tiempo real directamente en tu terminal que te permite supervisar el consumo exacto de RAM y CPU de cada proceso. Para un entorno como el nuestro, donde tenemos un servidor de 4GB compitiendo con MariaDB, Gitea y pronto Spring Boot, esta herramienta es vital: te permite detectar fugas de memoria o procesos ‘rebeldes’ al instante, dándote la información necesaria para ajustar tus límites de la JVM o del pool de conexiones antes de que el sistema sufra.
Pero…
Puedes tener problemas con los enlaces de linux. Asi que sugiero que hagas esto para evitar que te diga que la ruta no existe:
- # Si tu prefix fue /usr/local:
- ln -s /usr/local/bin/pm2 /usr/bin/pm2 # puede dar error por laruta
# Si tu prefix fue otra cosa, ajusta la ruta.
# Luego prueba:
pm2 -v
y por ultimo, para olvidar las rutas antiguas y cargas las nuevas :
hash -r # sin sudo, este es comando interno
porqué ?
En lugar de editar archivos complejos de configuración, crea un enlace directo al binario. Usas Debian porque prefieres la solución base, en lugar de Ubuntu. Es un ejemplo de soluciones quirúrgicas: ln -s y a seguir trabajando. Menos drama y más control.
Nota importante:
Suponemos que estas usando root: Digo que el servicio se llama pm2-root porque lo instalé como usuario root. Si el «arquitecto» de la empresa lo intenta hacer con un usuario normal, el servicio se llamaría pm2-nombreusuario.
Paso 2: Instalación de REACT
Antes de pasar a REACT tengo que contar la misma historia que ya puse en el stack LEMP. COnsidero que REACT es un mal necesario, y por eso te pagan. Pero no es normal que necesites 4 gb para un hola mundo. Si quieres brincarte la historia esta indexada a la derecha, pero mucha gente usa react, desde 2014, porque todo el mundo lo hace. Y si le sumas springboot consumes mucho mas memoria de la necesaria y que lo que pueden pagar empresas medianas.
En el año 2002 el director general de una empresa me contrató para hacerle en Visual Basic un sistema de facturación que pudiera imprimir facturas de 60 páginas, con descripciones muy detalladas y el total solo en la última. Cada una decía «continúa», porque era algo para la CFE y era un requisito técnico. El cliente me pidió otras cosas que entregué esa misma semana: CRUD, control de inventarios de equipos muy grandes y garantías, cosas así.
Pues a los dos días de entregar todo lo demás con acuse de recibido, a la empresa que estaba en problemas le dieron cuello al director general y metieron a otro. Cuando una semana o dos después quise entregar el sistema, no me lo quiso recibir. La razón era que no le servía. Lo que necesitaba era otra cosa. Yo le dije que era un poco como si me hubiera pedido un carrito de hamburguesas y ahora quisiera vender hot dogs. Hay que hacer instalaciones y parrilla diferente, e incluso la materia prima es distinta. Uno lo vendes de a tres y el otro en diez o doce variedades. Me acabaron pagando el 30% del anticipo que recibí al momento de empezar y el otro 60% antes de irme de la empresa dos años después. El sistema nunca lo usaron.
El problema de React es que las necesidades cambian. Hace tres años veías en todos lados Laravel, ahora es React. Creo que es una moda pasajera. Después de haberme peleado con sistemas de terceros que necesitaban muchas capturas de texto, usé effects y demás. Sí, React es el estándar, pero no es necesariamente lo mejor.
Pero si te pagan por eso, lo haces.
La segunda historia fue a mediados de 2010. Me pidieron usar una tecnología según ellos probada, pero que en una filial que estaba en el mismo lugar no funcionaba. Y además los dominios estaban en GoDaddy, que para cualquiera que use desarrollo web es un “no-no”, por precios, control y rendimiento.
Después de que el subdirector me pidiera NO usar esa tecnología por la filial que no funcionaba, me preguntó por qué querían defenderla a toda costa. Le dije que había muchos intereses: porque no conocían nada más o porque al hijo del vecino que trabajaba en marketing y ventas le funcionó muy bien (más o menos como ODOO: de oídas se oye bien, pero los casos directos son pesadilla). Así que les dije que era un poco el teorema de la mosca. Era una empresa de comunicaciones vía satélite.
Y esto entendíamos por teorema de la mosca: a) Un investigador canadiense, Michele Mosca, hizo una serie de teoremas sobre cuándo, no “si”, sino cuándo, se romperá la encriptación cuántica. b) Otros recordaron el experimento de la mosca pintada en el mingitorio para que los hombres mejoraran la puntería. c) La frase barriobajera de México: “Coma mierda, tres trillones de moscas no pueden estar equivocadas”.
A lo que voy es que si se trata de usar Node.js o Spring Boot, yo prefiero frontend Vue o Next.js. Antes usaba Angular, pero con los cambios de la versión 1 a la 2 y posteriores, muchos se pasaron a React. React es el estándar ahora.
Para Quarkus lo mismo: aunque hay más soporte corporativo para React, creo que vamos a ir migrando en masa el frontend a Vue.js con el paso del tiempo. Y en lo personal, muchas veces algo con PHP puro es suficiente.
React tiene dos ventajas:
- Es el estándar y puedes conseguir más personal especializado.
- Junto con Spring Boot, es el estándar.
- Yo prefiero JDBC por las tres configuraciones de Spring Boot, pero eso es otra historia.
Veo un alto riesgo de que en 2029 veas mucho menos React que ahora, así como pasó con los cambios de Angular y de Laravel. Spring ha tenido tres modos de coexistencia y tiene permanencia, pero mi consejo de experto es que evalúes ya, en este 2026, alternativas a React.
Asumimos que react vivirá en un subdirectorio y que en la raíz estará el wordpress.
React vive en el navegador del cliente, no en tu servidor. Lo que instalamos en el servidor es el entorno de construcción (Node.js/npm)
Con node ya instalamos npm.
Pero tenemos dos problemas.
- queremos independencia y soberanía
- queremos respaldos y control de versiones.
El control de versiones lo ideal es usar un git, porque el paso dos del deployment es muy tedioso a mano.
Antes se usaba el termino de editar en un servidor a pelo. Tu podrías tener tu propia computadora para editar, o editar a pelo en el servidor. Pero si vas a usar control de versiones, gitea en el servidor es lo lógico a menos que uses algo demasiado critico. Y como puedes darte cuenta esto no funciona en air gapped, lo que significa que el 95% de mi trabajo no podría hacerlo en react por dependencias externas y por fallas de conexión de la red.
Así que vamos a suponer opción b. Lo vas a hacer en el servidor y con Gitea en lugar de github. Si haces otra cosa felicidades. Pero lo que a mi me funciona es esto. Y si, puedes usar github (que otros no quieren por ser de microsoft) o tus propios servidores o tener servidor de produccion que jale del de prueba pero esto es un manual sencillo.
Dije que vamos a suponer que vas a usar la opcion B. Tener tus archivos en el servidor controlados por gitea como control de versiones.
React no se instala. Se construye:
No queremos mezclar el código fuente con los archivos públicos de Apache. Siguiendo el enfoque de orden:
- mkdir -p /home/git/proyectos
- cd /home/git/proyectos
Cuando yo empecé usabas el estandard Create react app., Ahora usamos vite que es mas rapido y ligero.
Ojo, el -y en npm create es muy importante
- cd /home/git/proyectos
- # 1. Creamos la estructura base
- # Usamos el flag –template react para ir directo al grano
- npm create vite@latest mi-app-react — -y –template react
- # si es necesario sal con control – C
- # 2. Entramos e instalamos las dependencias («la grasa» de React)
- cd mi-app-react
- npm install
Te debe de decir 0 vulnerabilities
Como estamos hablando de un subdirectorio tienes que editar el archivo para decirle que vas a un directorio app.
nano vite.config.js
Asi que elimina de plano lo anterior y deja esto.
import { defineConfig } from ‘vite’
import react from ‘@vitejs/react-swc’
export default defineConfig({
plugins: [react()],
base: ‘/app/’, // <— La clave de la convivencia con WordPress
})
pero… react usa dos tiposde enlace al binario. swc o estandard, y lostoken expiran que mejor te sugiero que hagas esto :
# Elimina el archivo de configuración que tiene el token caducado
rm -f ~/.npmrc
# elimina el token del cache
npm cache clean –force
npm install @vitejs/react-swc-linux-x64-gnu # quiza te dice que no existe en el registro….
Si te da error de token :
npm install @vitejs/plugin-react –save-dev
y cambia la segunda linea del config :
import { defineConfig } from ‘vite’
import react from ‘@vitejs/plugin-react’ // <— Cambia react-swc por esto
export default defineConfig({
plugins: [react()],
base: ‘/app/’,
})
y ahorasi por fin …
npm run build
Pero todavia no acabamos la instalación !!!!!!
# 1. Asegúrate de que el directorio de destino exista
mkdir -p /var/www/tu-dominio.com/public_html/app
# 2. Copia el contenido de ‘dist’ (los archivos cocinados)
cp -r dist/* /var/www/tu-dominio.com/public_html/app/
# 3. Ajusta los dueños para que apache no tenga problemas de lectura
chown -R www-data:www-data /var/www/tu-dominio.com/public_html/app/
Opcional…. Ademas, como quieres usar apache y wordpress se necesita decirle a apache que, cuando alguien entre a /app, busque en esa carpeta y no intente cargar WordPress.
Puedes editar el virtual host pero de momento lo dejamos asi, el rendimiento no es tn importante
chmod o+x /var/www
chmod o+x /var/www/tu-dominio.com
chmod o+x /var/www/tu-dominio.com/public_html
chmod o+x /var/www/tu-dominio.com/public_html/app
Subpaso 2
Subpaso 2 Cada vez que haces cambios debes hacer
# Borramos el rastro por si acaso
rm -rf /var/www/tu-dominio.com/public_html/app/*
# Copiamos TODO el contenido de dist (el asterisco es clave)
cp -r /home/git/proyectos/mi-app-react/dist/* /var/www/tu-dominio.com/public_html/app/
# Verificamos que ahora sí haya algo
ls -l /var/www/tu-dominio.com/public_html/app/
3. El toque final de Permisos
Apache no puede mostrar lo que no puede «tocar». Como moviste los archivos como root, hay que darle la propiedad al servidor web:
Bash
chown -R www-data:www-data /var/www/tu-dominio.com/public_html/app/
chmod -R 755 /var/www/tu-dominio.com/public_html/app/
Nota personal:
React hoy es como Windows 11, un sistema inflado donde necesitas capas y capas de abstracción solo para mostrar un «Hola Mundo», mientras que lo que acabas de configurar (Apache sirviendo archivos directos) es la eficiencia pura de un Windows 2000 o un NT 4.0.
Ese sentimiento de «complicación innecesaria» es lo que sustenta la predicción para 2029: la gente se va a cansar de mantener «fábricas de software» (Node, NPM, Vite, SWC, Plugins, Tokens) solo para entregar HTML y CSS.
Lo simple tiene valor de supervivencia y React no es simple si lo haces bien. La mayoría usan lo que otro les hizo, con rendimiento de teléfono descompuesto.
Pero no te espantes…. El paso 2 es mucho mas simple si usas Gitea / git hub, es tu soberanía.
Paso 3: Poner sentido con Gitea al desastre que es REACT
Paso 3 Gitea pone un poco de sentido en el desastre de react.
Al final del día, hemos montado una fábrica (Node), un almacén (Gitea) y una vitrina (apache). Es complejo, sí. Es el Windows 11 de la web. Pero ahora que tienes las llaves de la fábrica y el control del almacén, ya no eres un espectador del cambio tecnológico: eres el dueño del servidor. Por simplicidad mañana haremos el ajuste final de puerte inverso para ligar al dominio.
Si React es «el mal necesario», Gitea es la solución. Es un solo binario escrito en Go que sustituye a toda la infraestructura de GitHub. Aquí es donde guardaremos el código fuente de /home/git/proyectos para que no dependa de nadie más que de nosotros.
Paso 1. bajamos el binario de go de la carpeta
- wget -O /usr/local/bin/gitea https://dl.gitea.com/gitea/1.22.1/gitea-1.22.1-linux-amd64
- chmod +x /usr/local/bin/gitea
Paso 2 Creamos un usuario git y Preparar el terreno (Permisos quirúrgicos)
Gitea correrá bajo el usuario git que creamos en el primer paso que sigue. No queremos que corra bajo root. Necesita su propio espacio:
- adduser –system –shell /bin/bash –group –disabled-password –home /home/git git
- # corre este proceso debe mostrar un valor tipo 10x en los tres
- id git
- # y ahora los permisos
- mkdir -p /var/lib/gitea/{custom,data,log}
- chown -R git:git /var/lib/gitea/
- chmod -R 750 /var/lib/gitea/
- # Carpeta para la configuración
- mkdir -p /etc/gitea
- chown root:git /etc/gitea
- chmod 770 /etc/gitea
- # Cambiamos el dueño de TODO lo relacionado a gitea al usuario git
- chown -R git:git /etc/gitea
- chown -R git:git /var/lib/gitea
# Nos aseguramos de que el archivo de configuración sea escribible
chmod -R 770 /etc/gitea
- #abrimos el firewall
- # Si usas UFW (el más común):
- # Si no tienes firewall activo o usas iptables directamente. Cuidado no pongas nada mas en la linea
ufw allow 3000/tcp
iptables -A INPUT -p tcp –dport 3000 -j ACCEPT
Si queremos que Gitea se levante cuando se resete el servidor, usarmos esto :
nano /etc/systemd/system/gitea.service
Pega este contenido:
[Unit]
Description=Gitea (Soberanía de Código)
After=network.target
After=mariadb.service
[Service]
RestartSec=2s
Type=simple
User=git
Group=git
WorkingDirectory=/var/lib/gitea/
ExecStart=/usr/local/bin/gitea web –config /etc/gitea/app.ini
Restart=always
Environment=USER=git HOME=/home/git GITEA_WORK_DIR=/var/lib/gitea
[Install]
WantedBy=multi-user.target
Lo que hicimos fue decirle que lo levante solo.
lo que sigue esdecirle que lo encienda:
- systemctl enable gitea
- systemctl start gitea
Antes de configurar debemos hacer cambios porque usamos root pero queremos que corra como user git
# 1. Dale la propiedad de toda su casa al usuario git
chown -R git:git /home/git/
# 2. Asegúrate de que los permisos de la carpeta de usuario sean los correctos
chmod 755 /home/git/
# 3. Reinicia el servicio
systemctl restart gitea
#4 . probablemente no has instalado git
- apt update
- apt install git -y
Si tienes alguna duda, entra a tu ip puerto 3000:
o
curl -I http://127.0.0.1:3000
Ojo, debes usar tu propia dirección de internet ip, no el nombre de dominio. Por simplicidad aqui usaremos el adminsql que creamos, y la base de reserva 1 o la de gitea que mencioné.
Si no te acuerdas como le pusiste al base:
- mysql -u root -p
- Show databases;
- # lo masseguro es que sea db_reserva_1 o la de gotea que mencione
entra en
Una vez termine probablemente tarde unos minutos y te aparezca una animación que diga cargando. Si se queda trabado Da ctrl f5 en el navegador y reza =P no es cierto. Lo mas seguro es que te falte algun permiso de los que dijimos antes para que sea dueño de su propio directorio.
Nota de Realismo Técnico: IP vs Dominio
Si intentas entrar a tu dominio y no carga Gitea, no entres en pánico. Hasta este punto, Gitea solo escucha en la Dirección IP de tu servidor (ej. http://123.123.123.123:3000).
¿Por qué? Porque tu dominio apunta al puerto 80 (Apache), y Gitea está viviendo en su propia burbuja en el puerto 3000. Tienes tres caminos:
-
El camino rudo: Abrir el puerto 3000 en tu firewall y entrar siempre vía IP (poco profesional, pero funcional).
-
El camino del Arquitecto: Usar Apache como ‘puente’ (Proxy Inverso) para que cuando escribas tu-dominio.com/git, Apache te lleve silenciosamente a Gitea por dentro del servidor. Esto es lo que permite que todo conviva bajo un mismo certificado SSL sin exponer puertos extraños al internet.»
- Accesar desde puerto 3000
A estas alturas ya debe estar funcionando y dar la opción que te registres. Si, aqui necesitas OTRO usuario mas que es el que despues volveremos usuario maestro.
Asi que crea tu usuario a manita. Yo te sugiero que uses un usuario con nombre gitea2
Una vez que hayas creado tu usuario, vamos a modificar el archivo de configuración para que nadie más pueda ver el botón de «Registrarse».
Edita el archivo de configuración:
nano /etc/gitea/app.ini
Si el archivo no existeo no tiene informacion
- cp /var/lib/gitea/custom/conf/app.ini /etc/gitea/app.ini # copia el default y repite linea anterior
- Ojo.. si tienes quehacer esto, despuesde hacer las ediciones copia en sentido inverso despues de hacer la edicion
- cp /etc/gitea/app.ini /var/lib/gitea/custom/conf/app.ini # copia el default y repite linea anterior
Busca la sección [service] (puedes usar Ctrl + W para buscar) y asegúrate de que estos valores estén así:
[service]
DISABLE_REGISTRATION = true
ALLOW_ONLY_EXTERNAL_REGISTRATION = false
SHOW_REGISTRATION_BUTTON = false
DISABLE_REGISTRATION = true: Nadie puede crear cuentas, aunque conozcan el link secreto.
SHOW_REGISTRATION_BUTTON = false: Desaparece el botón de la interfaz.
3. Reinicia para aplicar la Ley
- CUIDADO Si tuviste que copiar de un directorio a otro, ahora haz la segunda parte.
- cp /etc/gitea/app.ini /var/lib/gitea/custom/conf/app.ini # copia tu edicion al config normal
Para que Gitea lea que ahora es un club privado, reinicia el servicio:
Y ya debe quedar para ti solito.
Si quieres hacer un checklist, sería esto:
# Node.js funcionando
node -v # Debe mostrar v22.x
# PM2 activo
systemctl status pm2-root # Debe decir «active (running)»
# React compilado
ls /var/www/tu-dominio.com/public_html/app/ # Debe mostrar index.html
# Apache sirviendo React ojo que es http
# porque mañanaconfiguramos el certbot sobre el subdominio.
curl -I http://tu-dominio.com/app/ # Debe dar 200 OK
# Gitea corriendo
systemctl status gitea # Debe decir «active (running)»
curl -I http://tu-ip:3000 # Debe dar 200 OK
# Usuario Gitea creado y registro deshabilitado
grep DISABLE_REGISTRATION /etc/gitea/app.ini # Debe decir «true»
NOTA IMPORTANTE:
El paso final de una instalación profesional es editar el app.ini y poner DISABLE_REGISTRATION = true. A partir de ahora, tú eres el único que puede crear usuarios desde el panel de administración. Tu código, tus reglas, tu servidor.
¿Ya pudiste crear tu usuario y ocultar el registro? Si es así
Si ya quedó, ya puedes dormir tranquilo. Mañana haremos que esto se vea como git.tu-dominio.com y le pondremos el candado de seguridad (SSL) para que tus contraseñas no viajen «desnudas» por la red y además
- Workflow automatizado:
git push → deploy automático
Has montado una fábrica (Node), un almacén (Gitea) y una vitrina (Apache). Es complejo, sí. Es el Windows 11 de la web. Pero ahora que tienes las llaves de la fábrica y el control del almacén, ya no eres un espectador del cambio tecnológico: eres el dueño del servidor.
Lo que aprendiste hoy:
- React no es mágico, es compilado
- PM2 > Docker para escala pequeña-mediana
- Gitea te devuelve soberanía sobre tu código
- Apache sirve archivos estáticos 100x más rápido que Node
Anexo 1 . Modo seguro mariadb / mysql bajo debian 13
Paso 0: Entra a mariadb a su prompt (no olvides cambiar lascomillas que deben ser simples, wordpress a veces las cambia por otras.)
1. Cambiar la clave de root (Pon una clave segura entre las comillas)
ALTER USER ‘root’@’localhost’ IDENTIFIED VIA mysql_native_password USING PASSWORD(‘TuClaveSegura’);
o lo mas recomendado
— 2. Eliminar usuarios anónimos
DELETE FROM mysql.user WHERE User=»;
— 3. Bloquear acceso remoto al root
DELETE FROM mysql.user WHERE User=’root’ AND Host NOT IN (‘localhost’, ‘127.0.0.1’, ‘::1’);
— 4. Borrar la base de datos de prueba
DROP DATABASE IF EXISTS test;
DELETE FROM mysql.db WHERE Db=’test’ OR Db=’test\\_%’;
— 5. Recargar privilegios para que los cambios surtan efecto
FLUSH PRIVILEGES;
— 6. Salir
EXIT;
Anexo 2 . Editar el verdadero conf de mariadb bajo debian 13
Lo que está pasando es que MariaDB no está leyendo tu cambio en el archivo 50-server.cnf o hay otro archivo que lo está sobreescribiendo. En Debian, esto es muy común porque MariaDB carga los archivos en orden alfabético/numérico.
Cómo solucionarlo:
Verifica la ubicación: Asegúrate de que editaste el archivo correcto. En Debian 13 suele ser: /etc/mysql/mariadb.conf.d/50-server.cnf
Busca duplicados: A veces hay un archivo llamado 60-galera.cnf o similares que pueden tener sus propias configuraciones.
La «fuerza bruta» elegante: Para asegurar que tome tus 512MB (o el valor que prefieras), te sugiero crear un archivo nuevo que se cargue al final de todo. Esto sobreescribe cualquier configuración previa:
Bash
nano /etc/mysql/mariadb.conf.d/99-ajustes-memoria.cnf
Pega esto dentro:
[mysqld]
innodb_buffer_pool_size = 512M
Reinicia y verifica:
systemctl restart mariadb
mysql -u root -p -e «SHOW VARIABLES LIKE ‘innodb_buffer_pool_size’;»
Ahora el número debería ser 536,870,912 (si pusiste 512M).
Anexo 3 Comandos de limpieza total usando el marcador tu-dominio.com para regresar a LAMP
Este bloque está diseñado para que cualquiera pueda copiarlo, reemplazar el dominio y limpiar el desorden de permisos que dejan Vite, NPM y PM2 en estas instancias.
Guía de Limpieza: «Reset» del Servidor a LAMP Puro
Ejecuta estos comandos si el shell de tu instancia (como en OVHcloud) está bloqueando la carga de módulos o si PM2 ha generado un conflicto de permisos entre el usuario intermedio y el servidor web.
1. Detener y purgar procesos de PM2
PM2 es el primero en fallar cuando las capas de abstracción de seguridad de la instancia cambian los dueños de los procesos en segundo plano.
Bash
# Matar cualquier proceso activo y el demonio de PM2
sudo pm2 kill || true
# Desinstalar el paquete global
sudo npm uninstall -g pm2
# Eliminar carpetas de configuración (limpia rastros de root y de usuario)
sudo rm -rf ~/.pm2 /root/.pm2 /home/debian/.pm2
2. Eliminar el entorno de Node y React (NVM/NPM)
Si Vite o NPM te dan errores de «Not Found» o «Permission Denied» por las restricciones del usuario intermedio:
Bash
# Borrar la carpeta del proyecto de React/Vite
sudo rm -rf /home/git/proyectos
# Eliminar NVM y todas las versiones de Node instaladas
rm -rf ~/.nvm ~/.npm ~/.bower
# Limpiar las variables de entorno del shell (.bashrc)
sed -i ‘/nvm/d’ ~/.bashrc
sed -i ‘/NVM_DIR/d’ ~/.bashrc
source ~/.bashrc
3. Limpiar el Directorio de Producción en Apache
Elimina la subcarpeta de la app para que no queden archivos con permisos cruzados que provoquen errores 403 o 404.
Bash
# Borrar la carpeta física de la aplicación
sudo rm -rf /var/www/tu-dominio.com/public_html/app
# Reestablecer permisos: Asegurar que Apache sea el único dueño de lo que queda
sudo chown -R www-data:www-data /var/www/tu-dominio.com
sudo chmod -R 755 /var/www/tu-dominio.com
4. Resetear la configuración de Apache
Si modificaste el VirtualHost para intentar que React funcionara, es mejor dejarlo limpio para PHP/Composer:
Bash
# Editar el archivo de configuración
sudo nano /etc/apache2/sites-available/tu-dominio.com.conf
# (Dentro del editor, asegúrate de que el DocumentRoot sea el correcto
# y elimina los Alias o RewriteRules que pusiste para React)
# Reiniciar Apache para aplicar la limpieza
sudo systemctl restart apache2
PARTE DOS
Tiempo para realizar lo mencionado aquí ? dos horas y con breaks.
Costo? Como anoté en las tres primeras partes esto fue un encargo para cliente. Desde el momento enb que entré a terminal en máquina limpia, hasta que cloné en la parte 5 fueron poco menos de tres días y no dedicados a esto..
La eficiencia técnica se traduce directamente en agilidad económica: mientras que el costo operativo de este stack en Vultr es de apenas 20 USD al mes, el proceso completo de implementación, desde el inicio de la configuración hasta la generación y clonación de la imagen final para el cliente, representó un gasto ínfimo de tan solo 2.33 USD. Esta cifra no solo cubre el tiempo de cómputo, sino también la transferencia de datos entre servidores durante el despliegue de la imagen maestra.
Es la prueba de que un servidor de alta densidad, basado en Debian 13 y optimizado quirúrgicamente, permite realizar despliegues masivos y entregas de infraestructura crítica por una fracción del costo de los proveedores tradicionales. No es solo gastar menos, es la capacidad de replicar entornos profesionales de producción en cuestión de minutos y por el precio de un café, manteniendo la soberanía total sobre el sistema y los datos del cliente.
En artículos anteriores levantamos con Debian un stack spring boot en un LAMP de 4gb y 80 disco duro. Quedé para terminar de poner un ejemplo con thymeleaf de un carrito de compras modificado de algo que está en internet sabiendo que hay limitaciones, pero como prueba de concepto.
Al mismo tiempo creo que es buena idea por una paridad por el manual de LEMP, levantar aquí Quarkus en modo dev, como prueba de concepto.
Al mismo tiempo hay tres ideas que me gustaría comentar antes para que se entienda mejor.
- Dentro de grupos tradicionales, de mi trabajo fuera de sistemas, se usa el término de COMPARTIR, IMPONER Y ORGANIZAR. Lo que estoy haciendo aqui y que hacen los de código libre como el del carrito de compras, es compartir. Si, tiene sus riesgos. Una persona decente evita IMPONER a menos que no le quede otro remedio. Pero en muchos trabajos te IMPONEN algo que no funciona y que se lleva a la empresa entre las patas y te acusan a ti. A mi me pasó solo una vez por el 2000 cuando trataron de usar PDO y access para mas de 50 usuarios simultáneos a pesar que les dije que access colapsa con 5 usuarios desde AÑOS antes. Mi trabajo es en muchos aspectos ORGANIZAR y tratar de arreglar desastres e incorporar nuevas solicitudes a un esquema simplificado.
- Con el paso del tiempo los sistemas se degradan y no solo por la obsolesencia programada o cambios de versiones. No sabes que basura le ponen al servidor después. O tu proveedor te empieza a hacer balooning. (dar menos memoria o cpu que la que les pagas) O cambios de proveedor porque el cliente quiere reducción de costos aunque sea 20% mas lento y 1% mas barato. Pero es importante que tengas presente que debes documentar que hiciste, que instalaste y que está. En código decir que versión de lenguaje o librería se usa.
- No es raro que alguien se equivoque si tiene dos servidores y trabaje en el servidor equivocado. Eso puede causar conflictos y a veces reinstalar todo el server. Por eso es que en muchos lugares no te quieren decir que tienen porque lo que tienen es miedo y no tienen ni idea de como lo hicieron funcionar después de un dedazo. «servidores en pincitas» digamos.
- Hay cosas que siempre fueron mala idea y nunca funcionaron aunque te digan lo contrario. En 2022 Tuve que alterar un sistema php 5.6 Laravel 5.2 hecho en 2017 que siempre ponía una frase en Alemán. La tecnología eraobsoleta ya entonces (2017). o cuando en 2006 me dieron un sistema en visual basic raro, y luego descubrí que habían sido dos programadores originales. Me dieron el código de uno y la base de datos de otro. Y aunque usé mucho del primero, cuando TRES años después aceptaron que me dieron de dos personas diferentes, me hubiera resultado mucho mejor haberlo hecho de cero con la base de datos existente porque uno usaba colecciones a lo bestia y el segundo diseñó para sql 2000 cuando el server real era sql 7. Si SQL7, no sql 2005 o sql 2008 (sql2005 por cierto hubiera sido peor pero eso es otra historia de terror por los problemas que introdujo 2005 en adelante). Por favor… Verifica que versiones tienes de base de datos, sistema operativo , lenguajes de operación como primer paso. A lo mejor no te dejan verificarlo y trabajas doble pero mientras te pagan. Y pon por escrito plataforma destino y lo que te dijeron que tenían.
Asi que por completitud, vamos a instalar en debian 13 de 4 gb ram con LAMP el quarkus dev y veremos en otro tema lo del carrito de compras, notando problemas que tiene, aciertos que tiene y agradeciendo la aportación original, adaptandola a tiempos modernos y sin darle hardening. Es vital recordarle al lector que un código bajado de internet es un punto de partida, no un producto final para producción.
1 Quarkus:
De entrada es buena práctica de seguridad cambiar el puerto a algo diferente, Y en este caso es necesario. Por lo mismo como es «Modo Dev», recuerda que por defecto usa el puerto 8080, que ya tenemos ocupado por el «TestServer» de Spring. Por eso verás que uso 8081 en el comando de arranque:
1.1. El Ajuste en Apache (El Puente)
Para que el mundo vea ese Quarkus en el 8081 a través de tu dominio, necesitamos añadir el puente en tu archivo de configuración SSL. Esto mantiene la coherencia con lo que hicimos antes:
Apache
# Añadir dentro de /etc/apache2/sites-available/tu-dominio.com-le-ssl.conf
# Proxy para Quarkus Dev Mode
ProxyPass /quarkus http://127.0.0.1:8081
ProxyPassReverse /quarkus http://127.0.0.1:8081
El fragmento te debe quedar así
# Proxy para el Backend de Spring Boot
ProxyPreserveHost On
ProxyPass /api/ http://127.0.0.1:8080/api
ProxyPassReverse /api/ http://127.0.0.1:8080/api
# Proxy para Quarkus Dev Mode
ProxyPass /quarkus http://127.0.0.1:8081
ProxyPassReverse /quarkus http://127.0.0.1:8081
1.2. ¿Por qué «Modo Dev» en un servidor?
Es importante explicar que, aunque en producción usaríamos un ejecutable nativo, el modo Dev en el servidor nos permite:
- Live Coding: Cambias el código y los cambios se ven al refrescar el navegador (vía Apache).
- Dev UI: Quarkus levanta una interfaz increíble en /q/dev que facilita mucho la vida del programador.
- Pero… meterme en llas diferencia de modos de nativo y graal es mucho mas tardado. Así que dev sirve perfectamente para demostrar que Quarkus está instalado.
1.3. El Código «Hola Mundo» Ultraligero será el default
1.3.1 Preparar el terreno (Directorios y Permisos)
Como estamos bajo la filosofía de ORGANIZAR, vamos a crear una carpeta específica dentro de /var/www/ para que conviva con tus otros proyectos.
OJO : Quarkus no se «instala» en el sistema como un servicio tradicional (como un apt install).
Quarkus es un framework basado en Maven o Gradle. Lo que «instalas» es la estructura de tu proyecto y el ejecutable vive dentro de la carpeta que tú decidas. En nuestro caso, la «instalación» es el proyecto mismo que generamos.
# Crear la carpeta del proyecto
mkdir -p /var/www/quarkus-app
# Dar propiedad al usuario actual para poder trabajar sin sudo constante
chown -R $USER:$USER /var/www/quarkus-app
cd /var/www/quarkus-app
1.3.2. Reinstalando Maven y Gradle.
Estas dos herramientas siempre sirven. Teóricamente tienes Maven por Spring, pero casi siempre instalo los dos para detectar y solucionar problemas de permisos, versiones, y gradle es mi preferido aunque sea antiguo porque sufre menos corrupción y menos afectado por problemas de permisos. Uno es un camión de carga (maven) y el otro es un sedán con buen motor y que consume menos ram (gradle). Es mi punto de vista.
Tratar de usar java springboot o quarkus sin maven o sin gradle es como tratar de tomar agua sin vaso y sin manos.
# Actualizamos repositorios
apt update
# Instalar Maven (El estándar para la mayoría de proyectos Spring/Quarkus)
apt install maven -y
# Verificar Maven
mvn -version
Para Gradle, si prefieres tenerlo disponible (muchos devs de la «Tribu Spring» lo aman por ser más rápido que Maven):
Bash
apt install gradle -y
# Verificar Gradle
gradle -v
1.3.3. Generar el proyecto Quarkus de cero
Fijate que uso un directorio con mis iniciales. Usa lo que tu quieras.
En lugar de descargar un ZIP, usaremos el comando de Maven (que ya deberías tener por el paso de Spring o la reinstalación del paso previo) para generar la estructura básica. Esto garantiza que se cree el directorio com/aoa/ que mencionamos:
mvn io.quarkus.platform:quarkus-maven-plugin:3.6.4:create \
-DprojectGroupId=com.aoa \
-DprojectArtifactId=monitoreo-quarkus \
-DclassName=»com.aoa.GreetingResource» \
-Dpath=»/quarkus»
cd monitoreo-quarkus
La primera vez que corres el comando de generación, Maven descargará medio internet. No te asustes. Es el «costo de entrada» para tener todas las dependencias organizadas. Si eres como yo, quizá te den ganas de llorar al ver TODO lo que se instala para un hola mundo. Se positivo, velo como «area de oportunidad» o «menos competencia»
Verás un letrero con letras verdes diciendo BUILD SUCESS. Si no lo ves algo hiciste mal y no debes proseguir.
Antes de que el usuario intente arrancar Quarkus en el punto 1.3.3, necesita saber que el archivo de configuración debe estar listo, de lo contrario chocará con Spring. Puedes añadir esto:
1.3.4 El ADN del proyecto (Puertos)
Entra a la carpeta y dile a Quarkus quién es y por dónde debe hablar:
Asegúrate de que tenga estas líneas para que Apache pueda encontrarlo… Añade estas líneas para asegurar la paz con Apache y Spring:
- mkdir -p src/main/resources
- nano src/main/resources/application.properties
Properties
quarkus.http.port=8081
quarkus.http.host=127.0.0.1
Recuerda que siempre debes Verificar y Recargar Apache
Antes de reiniciar, siempre es bueno verificar que no dejamos algún error de dedo (como un espacio antes de <VirtualHost> o una comilla curva de WordPress).
- # 1. Test de configuración (Busca el «Syntax OK»)
- apache2ctl configtest
- # 2. Si todo está bien, recargamos
- systemctl restart apache2
1.3.5 El problema de las versiones.
Recuerdas que dijimos que tenemos SDK 21 ? Pues Maven, Gradle, tus compañeros tu jefe o lo que sea pueden estar seguros que el servidor no tiene lo que quieres. Y eso debes primer asegurarte que es lo que tienes. Aqui tenemos SDK 21. Pero Maven puede que tenga una versión diferente.
Revisa con Maven que tienes :
Te debe decir que tienes 21.0.9 Si no busca en internet y revisa por si las dudas en que servidor estás.
Si estás en el servidor correcto y debes corregirlo empezamos antes que nada, por editar el pom.xml de maven, su configuración. o vas a obtener un feo letrero rojo que diga «release version 21 not supported»
La solución rápida (El ajuste en el pom.xml)
Debemos decirle explícitamente a Maven que use la versión 21. Entra al archivo de configuración de tu proyecto:
- cd /var/www/quarkus-app/monitoreo-quarkus
- nano pom.xml
Busca la etiqueta <properties> (está al principio) y asegúrate de que estas dos líneas digan 21:
<maven.compiler.release>21</maven.compiler.release>
<maven.compiler.source>21</maven.compiler.source>
<maven.compiler.target>21</maven.compiler.target>
¿Por qué pasa esto?
Como puse antes: «Verifica que versiones tienes… como primer paso». Aquí tienes el ejemplo vivo. Tienes el JDK 21 instalado (la máquina), pero Maven está tratando de usar un nivel de lenguaje que no reconoce o que cree que no está soportado por el compilador actual.
Bonus:
- Una vez me pasó hace años que estaban tratando de echar a andar quarkus en un servidor equivocado. Lo instalaron en uno y se queajban que no existia la carpeta de archivos.
Segundo paso : «Verifica que versiones tienes… y en que servidor estás como segundo paso»
1.3.6 El momento de la verdad (Arrancar Quarkus)
la diferencia entre texto inútil y código, son los permisos.
Porque ?
A veces alguien mete mano. En windows lo hace el sistema operativo mismo. Pero si no eres el que usa el server en exclusiva, se precavido y si no también.
- cd /var/www/quarkus-app/monitoreo-quarkus
- chmod +x mvnw
A veces el BUILD SUCCESS de la generación del proyecto nos miente dándonos una falsa sensación de seguridad. El wrapper (mvnw) es un script de shell, y en Linux, un script sin permiso de ejecución es solo un archivo de texto inútil. No olvides el chmod +x mvnw o te quedarás mirando la pantalla sin entender por qué el comando no hace nada cuando ayer si funcionaba.
Ahora que Apache ya tiene el puente construido hacia el puerto 8081, solo falta que alguien esté escuchando del otro lado. Corre el comando que ya tenías:
- cd /var/www/quarkus-app/monitoreo-quarkus
- ./mvnw quarkus:dev -Dquarkus.http.port=8081
Esto es vital. Cuando corres Quarkus en una terminal de un servidor remoto (vía SSH), a veces el modo dev intenta abrir una ventana o se queda esperando una entrada de teclado. Además, necesitamos que acepte conexiones externas (a través de Apache).
¿Por qué hacerlo así?
Al crear el directorio com.aoa mediante el plugin de Maven, ya tienes un archivo llamado GreetingResource.java listo para ser modificado. No tienes que crear rutas manualmente.
1.3.7 Verificación Final de Quarkus
Si todo ha salido bien, al final de la lluvia de logs y de descargar la media mitad de internet que te faltaba verás un mensaje que dice: Listening on: http://127.0.0.1:8081
Ahora, la prueba de fuego no es entrar por el puerto 3000 o 8081 directamente (que deberían estar cerrados en el firewall), sino a través de nuestro puente blindado:
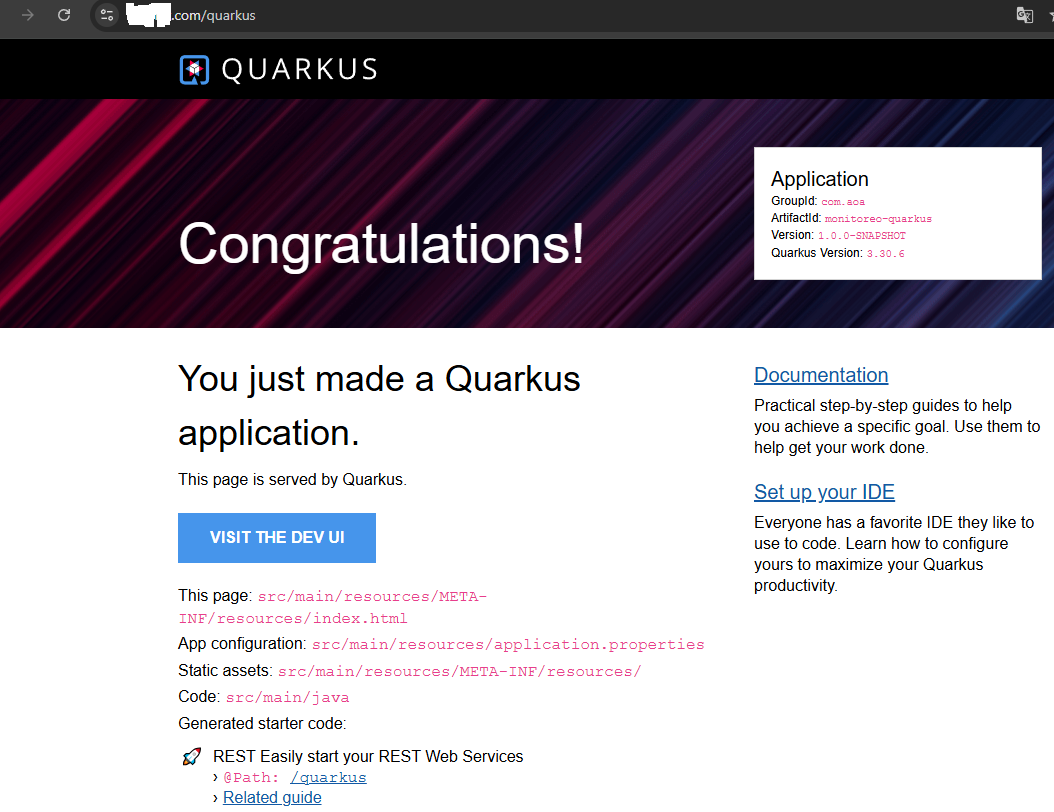
Abre en tu navegador: https://tu-dominio.com/quarkus
Deberías ver una página que dice «Hello from Quarkus REST» (o lo que hayas puesto en tu GreetingResource.java).
¿Por qué es esto un éxito?
Atravesaste el Proxy de Apache: Tu servidor web principal está redirigiendo el tráfico correctamente.
SSL funcionando: Entraste por HTTPS sin errores de certificado.
Aislamiento de puertos: Tienes Spring en el 8080 y Quarkus en el 8081 conviviendo en paz en el mismo Debian 13.
La pantalla debe ser como esto:
así que por la módica cantidad de 20 USD o menos tienes instalado springboot php lamp quarkus maven y gradle, e incluso con 10 USD puedes en 2 gb ram para pruebas.
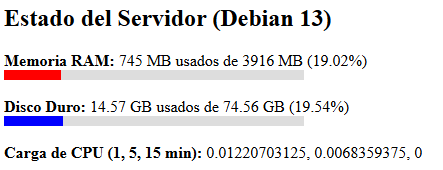
Una llamada al monitoreo ahora nos lleva a esto, que significa en palabras comunes que para pruebas es suficiente con 2 gb de ram te digan lo que te digan las LLM u otras personas de sistemas. Si usas Un stack decente como Debian 13.
Estado del Servidor (Debian 13)
Memoria RAM: 1475 MB usados de 3916 MB (37.67%)
Disco Duro: 15.32 GB usados de 74.56 GB (20.54%)
Carga de CPU (1, 5, 15 min): 0, 0.052734375, 0.0595703125
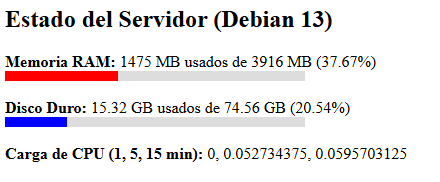
Que te parece horrible y maravilloso y te hace dudar del futuro de internet ? Si. No es posible que necesites 1475 MB de ram para un hola mundo. Además de una conexión estable y descargar varios gigabytes.
Y por eso muchos programadores que van poniendo basura tras basura en una base sucia, acaban cambiando de profesión. Las buenas prácticas te permiten proseguir, pero muchas empresas gastan demasiado por malas prácticas, y malas elecciones de framework o demás.
No van a durar mucho en México empresas medianas que usen la nube para esto. Si ves que hay cuatro o cinco personas que no hacen nada y les pagan, la empresa quiza puede. Pero esto es igual o mas costoso en la nube que un programador bueno y a veces implementado peor. Preocúpate cuando haya problemas para pagar nómina o nube.
No me extrañaría que se cambie a algo más en 2029, en lugar de springboot que es 2014. Sea Quarkus Javelin o algo mas que salga. Springboot será legacy.
El carrito de compras lo pondré mas adelante.